Linear indexes more documents with turbopuffer
Linear replaced Elasticsearch & pgvector to cut down ops and unify their search infrastructure. Cost wasn't the focus, but 70% savings has Linear thinking about indexing far more data.
70%
cost reduction
2B+
documents
13ms
p50 latency
4M+
namespaces
Their responsiveness and shipping velocity make us feel like we are their only customer.
Tom Moor, Head of Engineering
Why turbopuffer?
Linear was drawn to turbopuffer for its ability to ingest 100s of millions of full-text search documents & vectors without having to think about machine types. Instead, Linear can focus on shipping features.
Linear does hybrid search (FTS + vector) on multiple
(org_id, table) namespaces, rank fuse, and re-rank:
┌──────────────────────────────┐
│ ┌──────┐ ┌────────────────┐ │
│ │Linear│─▶│ Cohere │ │
│ │Query │ │ Embedding │ │
│ └──────┘ └──────┬─────────┘ │
│ ▼ │
│ ┌─turbopuffer queries────┐ │
│ │ Issues Vector │ │
│ ├────────────────────────┤ │
│ │ Issues FTS │ │
│ ├────────────────────────┤ │
│ │ Document Vector │ │
│ ├────────────────────────┤ │
│ │ Document FTS │ │
│ ├────────────────────────┤ │
│ │ Project Vector │ │
│ ├────────────────────────┤ │
│ │ Project FTS │ │
│ └───────────┬────────────┘ │
│ ▼ │
│ ┌────────────┐ │
│ │ Rank Fuse │ │
│ └─────┬──────┘ │
│ ▼ │
│ ┌──────────────┐ │
│ │ Cohere Rerank│ │
│ └──────────────┘ │
└──────────────────────────────┘Customer data security is critical to Linear. The ability to use customer managed encryption keys (CMEK) on a per namespace basis stood out.
Results
- Single system for vector and full-text search
- Zero-ops search for terabytes of data
- 70% reduction in cost, unlocking indexing far more data
turbopuffer in Linear
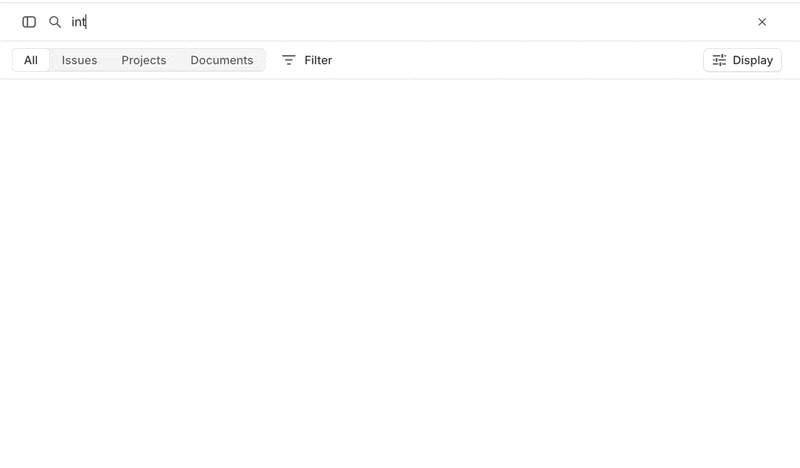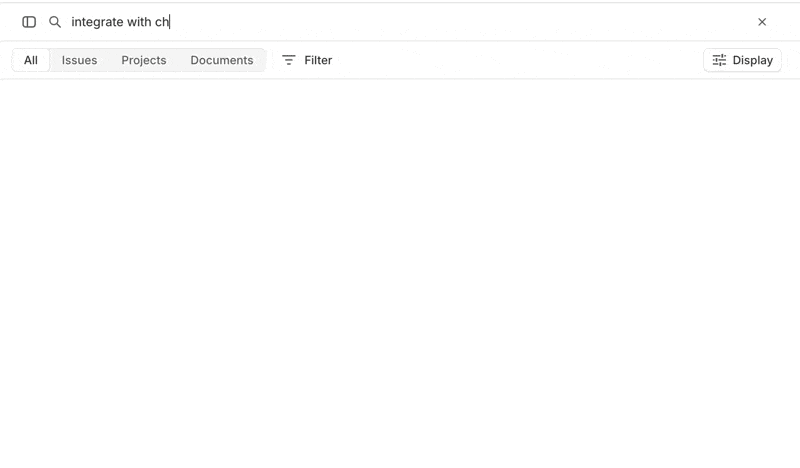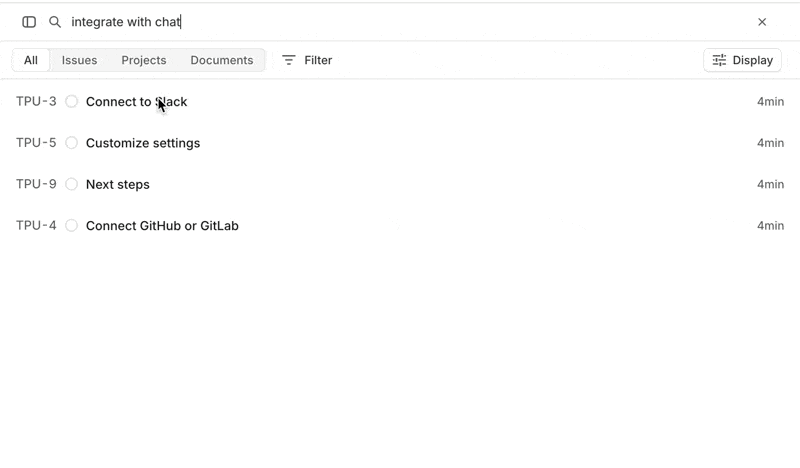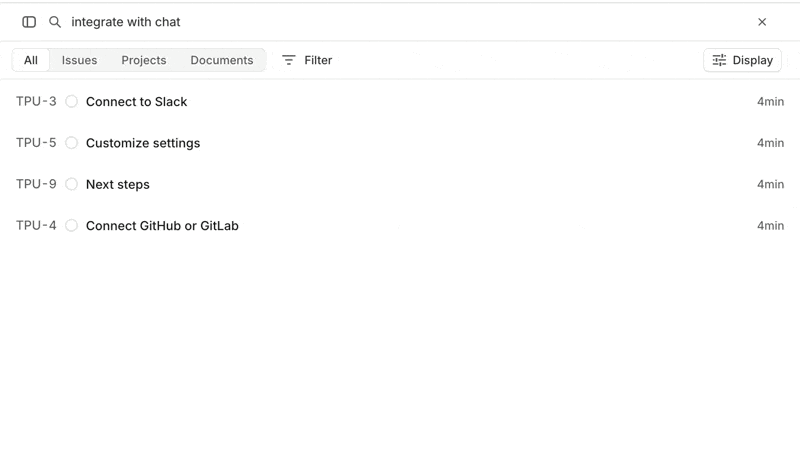
When a user submits a search, Linear will issue parallel queries across multiple namespaces (documents, issues, projects, comments, attachments, issues, and initiatives) using vector + FTS to return a list of results that then get passed into a reranker:
Linear also leverages turbopuffer for:
- Finding similar issues when a user opens a new issue
- Offering suggestions during issue creation, like which user should be assigned or which project the issue should belong to
- 🔜 Providing context to agentic workflows that are seamlessly integrated into the Linear experience
Linear plans to leverage turbopuffer to power all of their AI features.