Pylon shipped multi-tenant semantic search in 3 days
Pylon went from weeks of OpenSearch config hell to just tossing everything into turbopuffer and not thinking about it. Now they index more data, run more experiments, and ship AI features faster.
3 days
to production
50k+
namespaces
600M+
documents
24ms
p90 latency
We were running turbopuffer in production within two to three days of getting our API key.
Bennett Amodio, Engineer
Pylon is a B2B customer support platform that helps companies manage support tickets and customer conversations across Slack, email, and other channels.
The engineering team has been building AI features that can search customer documentation, knowledge bases, and past support tickets to help support team members respond to and resolve new issues faster with AI. These features require semantic search over customer data with strict isolation between tenants.
Why turbopuffer?
Bennett Amodio and Bryant Lin, engineers on Pylon's AI team, initially built semantic search on OpenSearch, since they were already using it for keyword search. They anticipated efficiency - their data was already indexed - but encountered "ops hell". The OpenSearch API was counterintuitive, depending on numerous config files and plugins.
Pylon's multi-tenancy requirements made it even more intractable. OpenSearch required minimum shards per namespace, each with fixed resource overhead. With hundreds of customers needing isolated namespaces, costs scaled linearly with tenant count regardless of actual usage.
Other semantic search providers passed the performance bar, but - like OpenSearch - had pricing models where costs would still scale linearly with tenant count, prohibitive for Pylon's multi-tenant workload.
What Pylon wanted: a semantic search engine with a simple API and costs that would scale not based on how many indexes they had, but how much they used those indexes. turbopuffer stood out for a few reasons:
-
Object storage-native architecture: Both Bennett and Bryant have backgrounds working for storage companies. turbopuffer's object storage-native architecture clicked: durable, low-cost storage for cold data, memory/SSD caching for warm data. The architecture aligned with Pylon's multi-tenant workloads, as only a subset of customer namespaces are active at any time.
-
Transparent trade-offs: Both engineers appreciated that turbopuffer's website was upfront about tradeoffs, limits, and guarantees. This signaled engineering rigor and, in Bennett's words, "intellectual honesty."
-
Usage-based pricing: Costs scale with usage, not tenant count.
They had turbopuffer running in production in just 3 days, compared to weeks configuring OpenSearch - and that's with the time Bennett spent writing his own Go client (the official turbopuffer Go client library didn't exist yet).
turbopuffer is very well-loved at Pylon. I can't think of anybody who has worked with turbopuffer who has not had a really top tier experience.
Bennett Amodio, Engineer
Results
- 3 days to production (vs. weeks OpenSearch)
- 20k+ namespaces with no per-namespace cost overhead
- 300M+ documents indexed
- 24ms P90 query latency
turbopuffer in Pylon
Pylon's first AI feature was an agent that could search existing issues and documentation to help human support teams more quickly generate accurate responses to new issues. Since migrating that feature to turbopuffer, they've built several more:
- AskAI: A chat interface for Pylon's customers to ask questions about their underlying support issue data
- Knowledge Gap Detection: Semantic clustering to find issues not covered by existing documentation
- Feature Requests: Clustering and analysis of customer feature requests
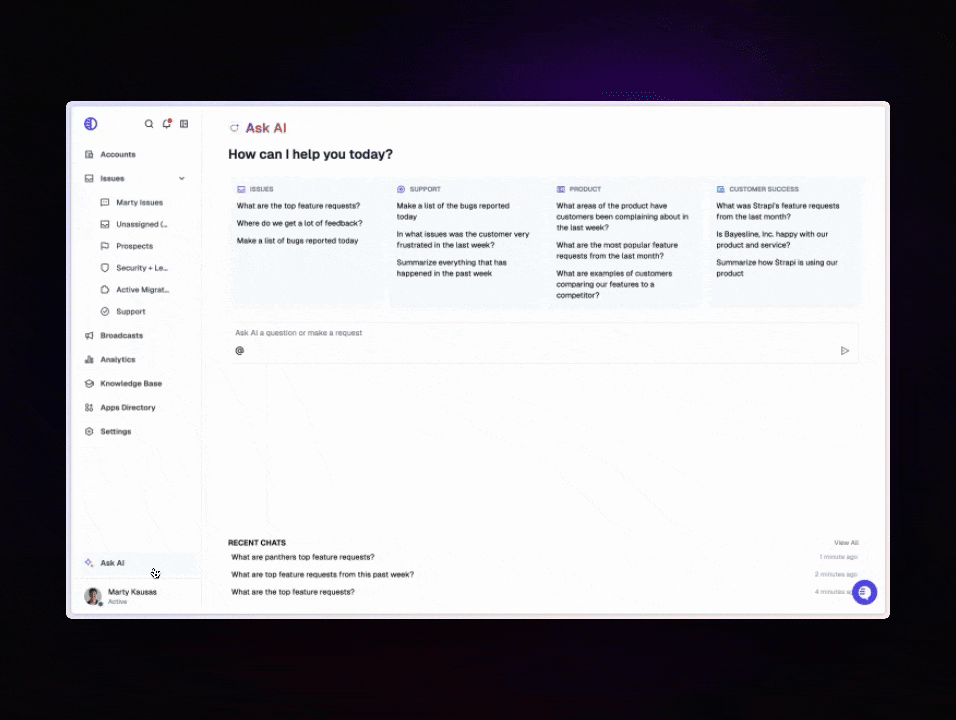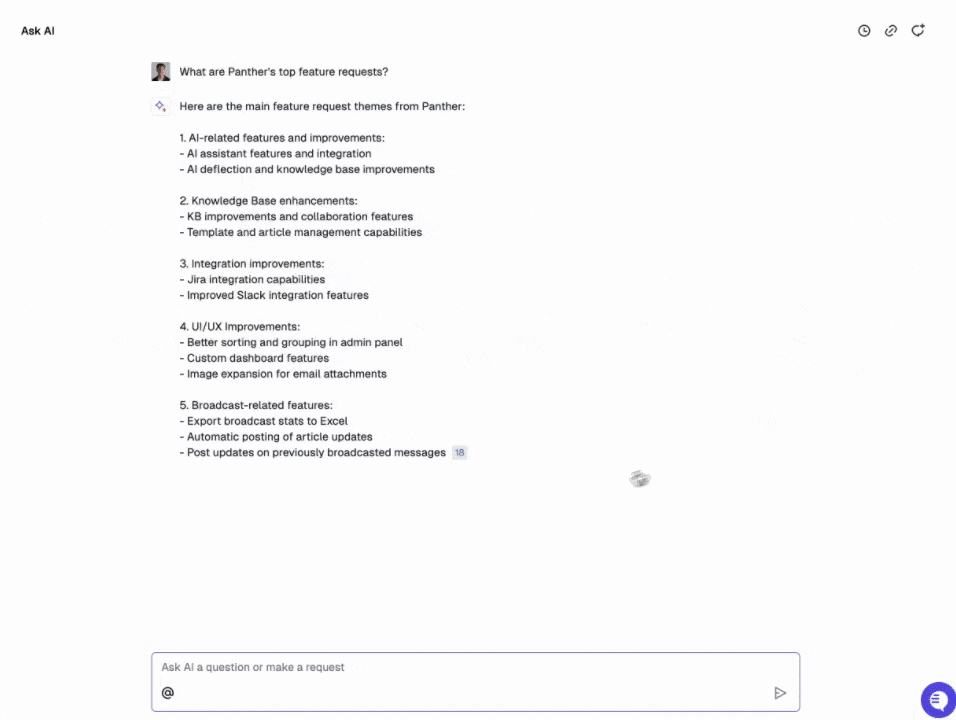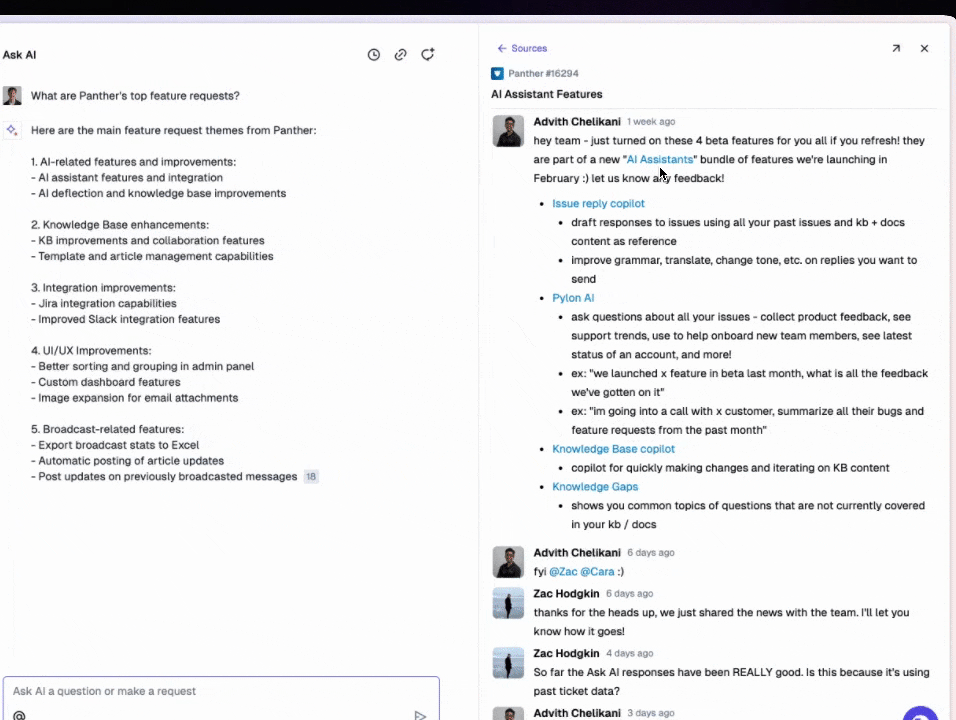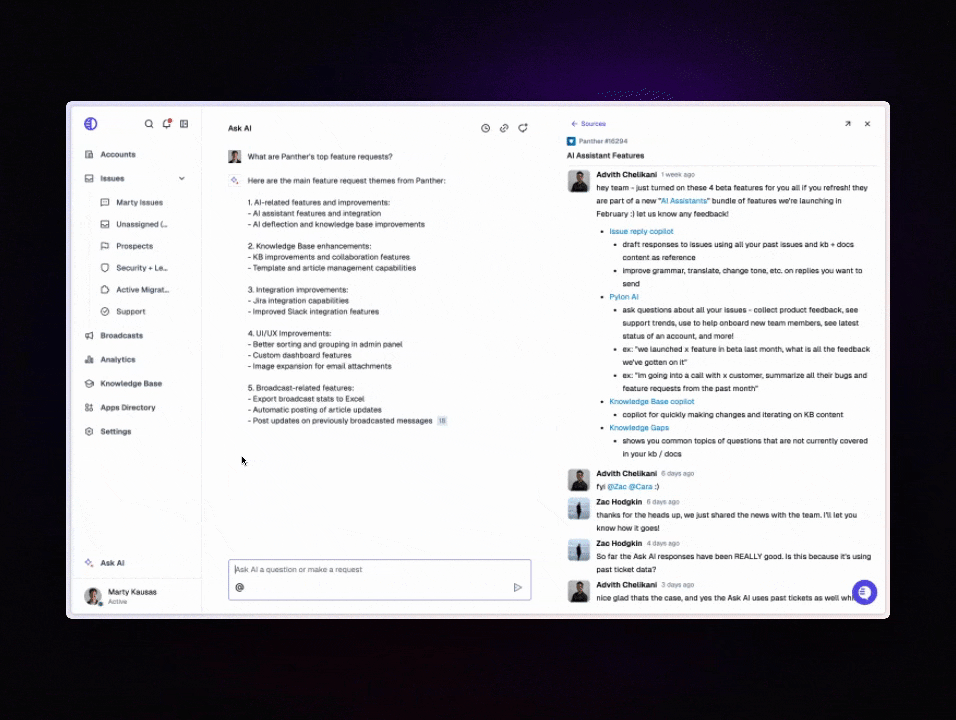
Each Pylon customer maps to a turbopuffer namespace for data isolation. Active namespaces are cached on SSD for low-latency queries. Inactive namespaces fade to object storage, keeping costs proportional to usage rather than tenant count.
Index everything, worry about nothing
When storage and indexing costs are low enough, the calculus shifts from "what data is worth indexing?" to "what data do we have?" The tpuf mindset changes how Pylon approaches AI feature dev.
Background reindexing: Pylon runs periodic jobs to reindex all data for consistency. With traditional providers, full reindexes could cost $1k-10k - enough to require some financial planning. With turbopuffer, the cost is low enough that they just do it.
Embedding upgrades: Upgrading embedding models or testing new chunking strategies requires reindexing entire namespaces. turbopuffer lets Pylon run more embedding experiments without second-guessing.
Indexing more data: Pylon is building infrastructure to bring more object types into turbopuffer. They're adding more data and more context to build better AI without the cost anxiety.
turbopuffer is uniquely enabling us. In the past it wouldn't be worth spending the money to iteratively improve our feature or add a new data source. With turbopuffer it costs comparatively nothing.
Bennett Amodio, Engineer
What's next for Pylon
Pylon is expanding their turbopuffer usage:
- More data: Indexing additional object types to improve context
- Full-text search migration: Evaluating moving full-text search from OpenSearch to turbopuffer to consolidate on a single search infrastructure
- Multi-query strategies: Testing rank fusion across query types using turbopuffer's multi-query API