Continuous recall measurement
All vector databases make a fundamental trade-off between query latency and accuracy. Because what's not measured is not guaranteed, turbopuffer automatically samples 1% of all queries to measure the accuracy of the vector index in production (recall). The automatic measurement results are continuously monitored by the turbopuffer team. Let's dig into why continuous recall measurement is paramount for any database that offers vector search.
For vector search, the naive approach is to exhaustively compare the query vector with every vector in the corpus. The query latency of this approach breaks down when you search 100,000+ vectors.
To reduce query latency, search engines use approximate nearest-neighbour (ANN)
indexes (such as
HNSW,
DiskANN,
SPANN) to avoid exhaustively searching the
entire corpus on each query. For the simplest type of index (inverted index), we
can expect a ballpark of sqrt(sqrt(n)) * sqrt(n) * q vectors searched per
query, where q is a tunable to make an accuracy/performance trade-off.
Some napkin math ballparks (~3 GiB/s SSD) comparing exhaustive and ANN performance on 1536-dimensional f32 vectors:
| Vectors | Exhaustive (SSD) | ANN (SSD) |
|---|---|---|
1k | 2 ms | 0.3 ms |
10k | 20 ms | 2 ms |
100k | 200 ms | 10 ms |
1M | 2 s | 60 ms |
10M | 20 s | 350 ms |
100M | 3.5 min | 2 s |
1B | 0.5 h | 10 s |
However, approximate nearest-neighbour algorithms come at the cost of accuracy.
The faster you make the query (smaller q), the less the approximate results
resemble the exact results returned from an exhaustive search.
To make the 10M+ vector indexes fast, you need more tricks we will get into in future posts. These tricks also have the potential to reduce accuracy.
To evaluate the accuracy of our queries, we use a metric known as recall. Within the context of vector search, recall is defined as the ratio of results returned by approximate nearest-neighbour algorithms that also appear in the exhaustive results, i.e. their overlap. More specifically, we use a metric known as recall@k, which considers the top k results from each result set. For example, recall@5 in the below example is 0.8, because within the top 5 results, 4/5 of the ANN results appear in the exhaustive results.
ANN Exact
┌────────────┐ ┌────────────┐
│id:9,score:0│▒│id:9,score:0│▒
├────────────┤▒├────────────┤▒
│id:2,score:1│▒│id:2,score:1│▒
├────────────┤▒├────────────┤▒
│id:8,score:3│▒│id:8,score:3│▒
├────────────┤▒├────────────┤▒
│id:1,score:4│▒│id:1,score:4│▒
┣━━━━━━━━━━━━┫▒┣━━━━━━━━━━━━┫▒
│id:0,score:9│▒│id:4,score:8│▒
┗━━━━━━━━━━━━┛▒┗━━━━━━━━━━━━┛▒
▒▒▒▒▒▒▒▒▒▒▒▒▒▒ ▒▒▒▒▒▒▒▒▒▒▒▒▒
↑ Mismatch ↑To ensure turbopuffer meets 90-95% recall@10 for all queries (including filtered queries, which are much harder to achieve high recall on) turbopuffer measures recall on 1% of live query traffic and has monitors in place to ensure recall stays above our pre-defined thresholds. 90-95% recall@10 is a good balance of performance and accuracy for most workloads. To our knowledge, continuous recall measurement is not something any other search engine or database does.
We've found continuous recall measurement essential to guarantee high recall to our customers while shipping quickly. Internal evals have improved for some of our customers after moving to turbopuffer. It wasn't possible for them to measure their vector recall before, and in retrospect, got poor results. We plan to expose recall in the dashboard, and you can always call our recall endpoint directly.
In spirit of complete transparency, here's our live recall performance for our 10 largest customers directly from Datadog. You'll note that our average recall@10 (the second column) is strictly above 90% for all customers, and in many cases, well above it. For larger top-k values (first column), we perform even better.
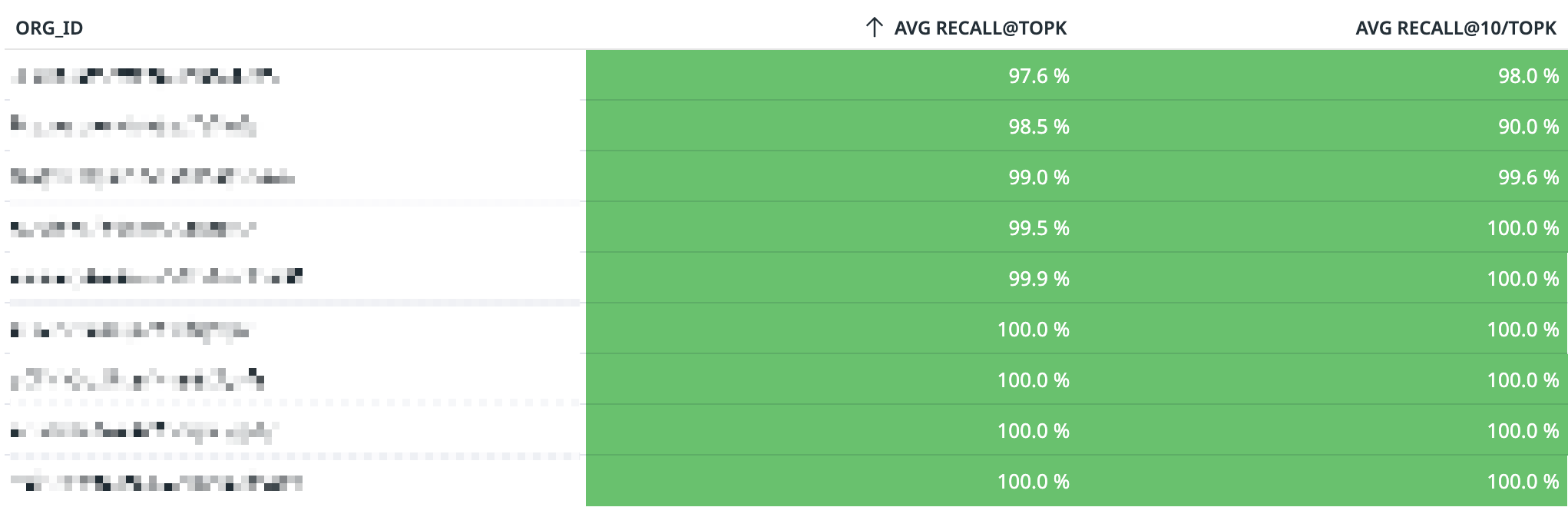
As we continue to optimize and make our system more efficient, we directly pass on performance gains to customers in both query latency and recall (by turning our accuracy sliders up). On a case-by-case basis, we're also able to tune knobs & configure our systems to get even higher recall if required by customers.
We've had continuous recall measurement since the early days of turbopuffer, and couldn't imagine trusting our ANN index with only the academic benchmarks we use for testing offline.
turbopuffer
turbopuffer is a fast search engine that hosts 4T+ documents, handles 10M+ writes/s, and serves 25k+ queries/s. We are ready for far more. We hope you'll trust us with your queries.
Get started